
第一章 开发基础
第二章 Python语言基本要素
第三章 简单数据类型
第四章 程序控制语句
第五章 组合数据类型
第六章 函数与模块
第七章 类与对象
第八章 文件处理
第九章 常见模块的使用
第十章 NumPy数值处理
第十一章 Pandas数据查询
第十二章 数据可视化
第十三章 机器学习
第一章 开发基础(点击代码可复制)
【代码 1-1】最简单的输出代码:
第二章 Python语言基本要素(点击代码可复制)
【代码 2-1】长语句的换行:
【代码 2-2】有注释的代码:
【代码 2-3】变量的基本使用:
【代码 2-4】变量的特殊赋值方法:
【代码 2-5】变量和函数同名产生的错误:
【代码 2-6】输入和输出的简单练习:
【代码 2-7】输出两个输入小数的总和:
【代码 2-8】有字符串变量:
str1 = '南京'
str2 = '江苏'
尝试使用多种字符串格式化方法完成输出:南京是江苏省会。其中的“南京”和“江苏”分别是strs1和strs2变量的值:
【代码 2-9】让用户输入一个整数长度,在“Python”中各个字符之间填充空格,使得总体字符串长度等于或者接近于输入的整数长度:
【代码 2-10】让用户输入两个数的加法计算式,如“1+2”,并输出最终的加法计算式及其结果,如“1+2=3”:
【代码 2-11】使用切片方法完成代码 2-10加法计算式的功能:
【代码 2-12】使用eval函数完成代码 2-10加法计算式的功能:
【代码 2-13】使用exec函数实现允许用户输入代码并运行:
第三章 简单数据类型(点击代码可复制)
【代码 3-1】二进制整数转换为十进制:
【代码 3-2】浮点数的科学计数法表示:
【代码 3-3】精度更高的浮点数表示法:
【代码 3-4】数字类型的常见代数运算:
【代码 3-5】在机器学习方法的数据预处理过程中,常常需要把连续型的数值映射为离散型的枚举数值。比如将人的年龄转换为年龄阶段,23岁可以映射为“20岁阶段”。请完成相应的代码功能:
【代码 3-6】在机器学习方法的数据预处理过程中,常常需要将多个数值映射到指定数量的数值区间,比如对所有输入的整数都映射到3个分类中。请完成相应的代码功能:
【代码 3-7】多行字符串的不同表示方法:
【代码 3-8】利用编码规律实现大写字母向小写字母的转化:
【代码 3-9】布尔类型的常见逻辑运算:
第四章 程序控制语句(点击代码可复制)
【代码 4-1】决策树是一种常见的机器学习算法,它模拟了人类在面对决策问题时所采用的思考方式,通过一系列的条件判断,最终得出决策结果。在决策树中,每个内部节点都代表了一个特征属性的测试,每个分支则代表了测试的一个可能结果,而每个叶子节点则存储了一个对于类别的判断结果或一个预测的数值。当要对一个新的样本进行分类或预测时,可以从决策树的根节点开始,根据样本的特征属性值沿着树向下移动,直到到达一个叶子节点,该叶子节点所存储的类别或数值就是最终的决策结果。
现已知一种可以根据当前温度、湿度和是否下雨来判断是否适合外出散步的决策树:
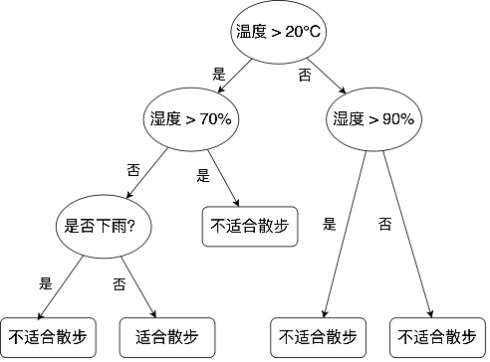
请实现上述决策树中当温度大于20度时,根据湿度是否大于90%来判断是否适合散步的过程
【代码 4-2】在代码 4-1基础上,完整实现该决策树的全部判断过程:
【代码 4-3】输出1到100以内所有奇数:
【代码 4-4】输出3到100以内所有素数:
【代码 4-5】使用while语句重写代码 4-3,输出1到100以内所有奇数:
【代码 4-6】PageRank算法是一种常见的网络权值迭代算法,主要用于诸如互联网网页的质量测度。基本计算原理是根据网页自身的链出将原始权值进行扩散,并通过多轮迭代获得稳定的收敛值来表征网页自身的最终权值。基本计算公式为:
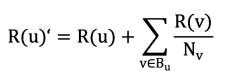 其中R(u)'和R(u)分别表示网页u的新权值和上次计算的旧权值,Bu表示网页u的链入网页集合,Nv表示网页u的一个链入网页v全部的链出数量。下面通过一个例子说明基本计算方法。
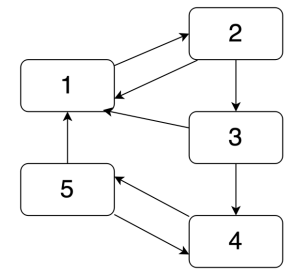
假设有5个网页,链接关系如:
其中R(u)'和R(u)分别表示网页u的新权值和上次计算的旧权值,Bu表示网页u的链入网页集合,Nv表示网页u的一个链入网页v全部的链出数量。下面通过一个例子说明基本计算方法。
假设有5个网页,链接关系如:
 初始设置每个网页的权值都为0.2,即网页总数分之一。
第一轮计算为:
初始设置每个网页的权值都为0.2,即网页总数分之一。
第一轮计算为:
 再加上每个网页各自的原始权值,可以得到第一轮计算后每个网页的新权值,即:
再加上每个网页各自的原始权值,可以得到第一轮计算后每个网页的新权值,即:
![]() 利用权值总和(为2)去除每个权值得到规范化后的权值为:
利用权值总和(为2)去除每个权值得到规范化后的权值为:
![]() 以此类推,再次使用该权值迭代进行相同的计算,反复计算后即可得到最终每个网页的权值。
以此类推,再次使用该权值迭代进行相同的计算,反复计算后即可得到最终每个网页的权值。
【代码 4-7】使用while、break和continue语句重写代码 4-3,输出1到100以内所有奇数:
【代码 4-8】实现直接退出两层循环。如被乘数从1到5依次循环,每个被乘数都和2个输入的整数进行乘积运算,如果一旦输入的乘数为0,立刻结束所有循环:
【代码 4-9】将输入整数作为分母,输出该分数的浮点数值。要求使用异常捕获实现对各种错误的处理:
【代码 4-10】在代码 4-9基础上,使用异常触发增加对负数分母的提示:
第五章 组合数据类型(点击代码可复制)
【代码 5-1】实现矩阵相加计算,如:
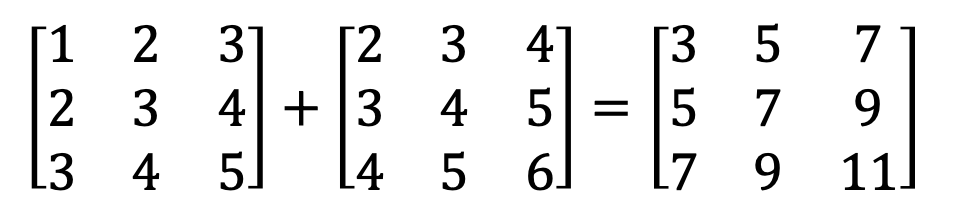
【代码 5-2】排序是各类机器学习方法中一种非常基础的算法,常见的方法有选择排序、冒泡排序、希尔排序和归并排序等。其中选择排序每次从待排序列中选出一个最小值(或最大值),然后放在序列的起始位置(或末尾位置),直到全部待排数据排完即可。请利用选择排序算法对列表元素进行排序:
【代码 5-3】判断列表为空的多种方法:
【代码 5-4】使用序号来循环遍历列表次数不会受到列表元素增减的影响:
【代码 5-5】使用直接循环遍历列表的次数会受到列表元素增减的影响:
【代码 5-6】利用梯度下降方法可以进行线性回归拟合。具体方法包括以下步骤:
①定义线性回归模型:假设线性回归模型为:
![]() 其中y是价格,x是面积,m是斜率,b是截距。
其中y是价格,x是面积,m是斜率,b是截距。
②定义损失函数:使用均方误差(MSE)作为损失函数,即:
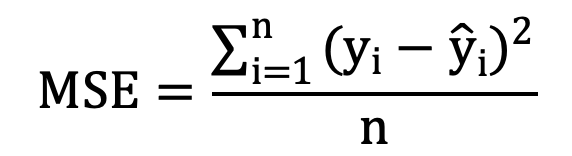 其中,其中yi是真实面积,
其中,其中yi是真实面积,![]() 是预测面积。
是预测面积。
③梯度下降:通过迭代更新m和b来最小化损失函数。在梯度下降计算时,每次迭代都需要更新初始设置的m和b,具体的更新增量可以使用损失函数求导来计算,比如在使用均方误差作为损失函数时,可以使用该损失函数的导数来计算m和b的增量,即:
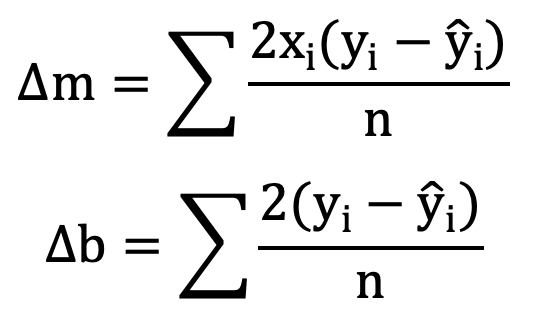 ④预测:使用训练好的模型预测指定面积时的房屋价格。
④预测:使用训练好的模型预测指定面积时的房屋价格。
假设有房屋面积和价格数据,具体如列表内容所示:
areas = [120, 200.5, 80, 140, 90] # 面积
prices = [170.5, 210, 135.2, 180, 150.5] # 价格
请使用线性回归进行拟合,并预测当面积为100时的房屋价格:
【代码 5-7】在文本分析应用中,文档的词频统计通常是进行词语权值设计和语义相关性测度的基础性工作。请利用字典结构,实现对文本关键词的词频统计:
【代码 5-8】在文本分析应用中,文档关键词的TF-IDF计算是一项基础性词项权值设置方法。其中TF是指词频,即文档中包含词语的个数,IDF是指倒文档频率,计算公式为:
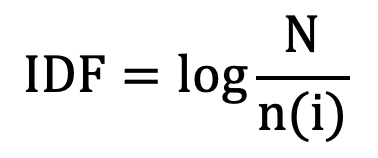 其中N表示文档总数,n(i)表示含有关键词i的文档总数。假设有三篇文档:
其中N表示文档总数,n(i)表示含有关键词i的文档总数。假设有三篇文档:
Python is a computer language of AI
Java is also an important computer language
Learning Python is a very important thing in Python era
请编写计算每篇文档每个关键词TF-IDF权值的方法:
【代码 5-9】删除出现在其他列表的列表元素:
第六章 函数与模块(点击代码可复制)
【代码 6-1】K近邻算法(K-Nearest Neighbors,简称KNN)常应用于各种分类任务中,算法认为如果一个样本数据在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。已知数据点及其所在的类别如:
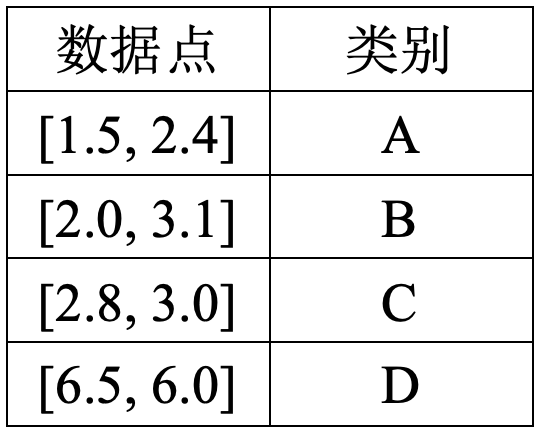 为简化问题,请通过计算查询点(2.5,2.5)与已知数据点之间的欧几里得距离,找到距离最近的2个邻居类别。要求使用不同自定义函数来划分各种基本计算功能。
为简化问题,请通过计算查询点(2.5,2.5)与已知数据点之间的欧几里得距离,找到距离最近的2个邻居类别。要求使用不同自定义函数来划分各种基本计算功能。
【代码 6-2】利用递归函数调用反转字符串:
【代码 6-3】利用递归函数可以实现决策树生成。
主要过程包括:
①实现基尼不纯度的计算,该指标可以衡量数据集纯度的一个指标,值越低表示数据集越纯净。当完全纯净时表示已经无需再进行判断分支的添加。
首先确定标签列表中有多少种类,对于每个标签类别,分别计算它在标签列表中出现的次数占总样本数的比例。通过计算每个类别比例的平方和,然后用1减去这个和,得到基尼不纯度值。计算公式为:
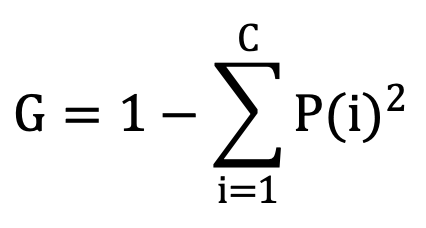 其中C为不同类别的总数,P(i)是第i个类别的出现比率。
其中C为不同类别的总数,P(i)是第i个类别的出现比率。
②实现最佳分割点,通过遍历每个特征所有可能的分割点,计算每个分割点的基尼不纯度,并选择基尼不纯度最低的分割点作为最佳分割点。
首先对于每个特征(通过i索引),获取该特征的所有唯一值作为可能的阈值(thresholds),并使用相邻两个阈值平均值作为候选阈值。其次,对于每个候选阈值,将数据集分为左子集和右子集。如果某个子集为空,则跳过该阈值。同时,计算左子集和右子集的基尼不纯度,并加权求和得到总的基尼不纯度。最后,如果当前阈值的基尼不纯度小于当前最优的基尼不纯度,则确定最优分割点。
③递归构建决策树,根据设定的最大深度或数据集无法进一步分割(所有标签都相同或者基尼不纯度为0)的情况停止递归,并返回叶节点的值。否则,它会找到最佳分割点,分割数据集,并递归地构建左右子树。
已有电商企业订货数据,给出了该企业商品采购与否的已有情况:
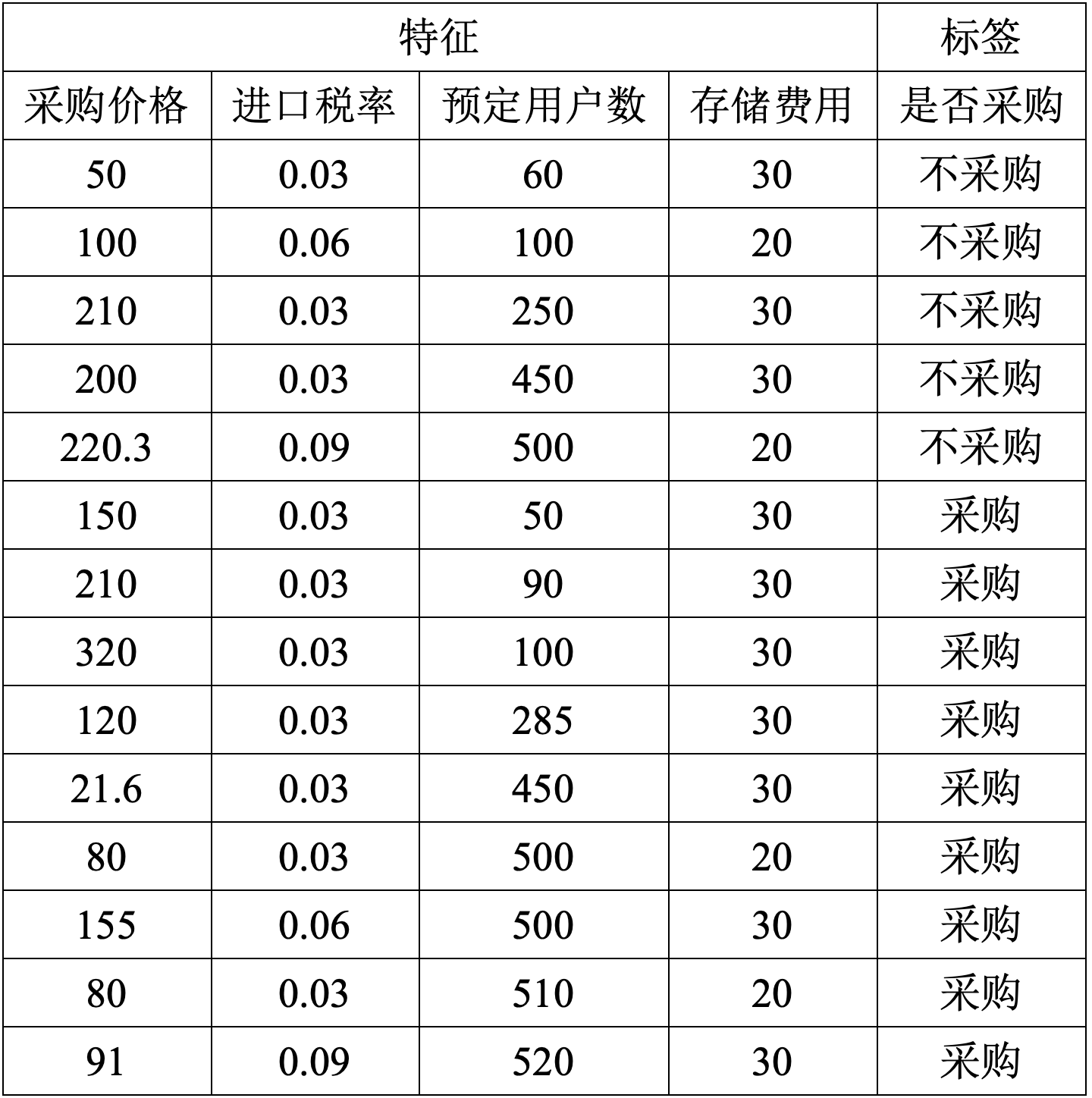 请给出利用递归函数生成决策树的代码。
请给出利用递归函数生成决策树的代码。
【代码 6-4】神经元是神经网络的基本单位,可以接受多个数值输入,对其做一些数据操作,然后产生一个输出。比如图展示了一个2输入的神经元:
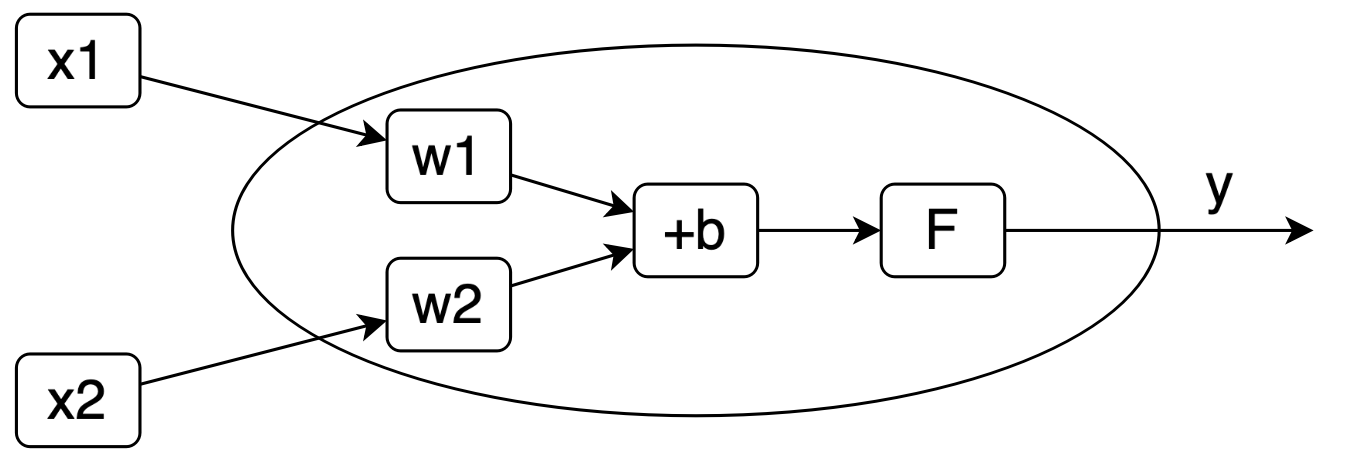 当x1和x2两个数值传递过来时,该神经元首先分别使用w1和w2权值去进行加权求和,然后加上偏置b,再继续将计算结果传递给一个激活函数F形成最终的输出y。
当x1和x2两个数值传递过来时,该神经元首先分别使用w1和w2权值去进行加权求和,然后加上偏置b,再继续将计算结果传递给一个激活函数F形成最终的输出y。
请编写一个可以表达上述计算过程的神经元函数:
【代码 6-5】数据清洗和整理往往是各类机器学习方法必需的前期基础工作。对于各类组合数据,利用map和reduce函数可以极大的简化相关数据操作。
已知有字典数据统计了若干算法不同指标的性能:
data = [
{'name': 'CDAE', 'P@5': '0.45', 'P@10': '0.41', 'P@20': None},
{'name': 'Wide & Deep', 'P@5': None, 'P@10': '0.38', 'P@20': '0.318'},
{'name': 'NeuralCF', 'P@5': '0.419', 'P@10': None, 'P@20': '0.388'}
]
请给出每个算法的各个指标平均值,缺失值以该指标平均值来填充:
第七章 类与对象(点击代码可复制)
【代码 7-1】定义一个时钟类Clock,表达小时、分钟和秒的相关设置和格式输出:
【代码 7-2】完善代码 4-3时钟类Clock的定义,增加属性方法来访问属性:
【代码 7-3】编写表达一个字符的简单Token类,可以自动统计当前创建的类对象个数:
【代码 7-4】利用继承和多态完成时钟类和夏令时时钟类的设计,并动态以秒数更新时间显示:
【代码 7-5】时间序列分析是一种常见的机器学习方法,简单的有回归分析、ARIMA等方法,复杂的有循环神经网络(RNN)、长短期记忆网络(LSTM)等。相关时间序列分析都建立在时间序列数据的表达基础之上。
为方便讲解,本例使用类来封装各种时间数据单元,并使用继承方法得到时间预测类,根据最小二乘法实现了简单线性回归时序预测模型:
第八章 文件处理(点击代码可复制)
【代码 8-1】读取MovieLens数据集的数据文件“u.data”:
【代码 8-2】将输入内容写入文件:
【代码 8-3】重定位实现在“u.data”数据文件首行增加标题行:
【代码 8-4】在各种机器学习算法执行过程中,往往会产生很多错误。为了方便排查,常常使用日志文件将代码运行过程的一些关键信息和步骤保存下来,以便实时监控与调试,同时还可以记录系统在运行过程中的异常事件、方便开发者进行性能评价与优化。
编写一个简单的日志文件管理机制,可以记录代码运行的总次数和每次运行的时间:
【代码 8-5】Excel文件是一种常见的数据文件形式,具体包括两种常见格式,分别是扩展名为“xls”的传统文档格式,和文件扩展名为“xlsx”的2013年以后新版格式。有两个Excel文件,分别是“sales.xls”和“sales.xlsx”(具体可以从教材配套在线资源下载),里面都只有一个工作表,名称是“Sheet1”,内容为一些超市商品的基本信息。
读取“sales.xls”文件:
读取“sales.xlsx”文件:
【代码 8-6】以列表元素为名称批量创建多个文件夹:
第九章 常见模块的使用(点击代码可复制)
【代码 9-1】机器学习方法常常需要将数据文件划分为训练集和测试集。据此评价模型在未见数据上的泛化能力,确保模型不仅拟合训练数据,还能在实际应用中表现良好。
编写代码对“u.data”数据文件按照8:2随机划分训练集和测试集:
【代码 9-2】在很多机器学习方法测试中,需要大量仿真数据,这些数据常常遵守正态分布。正态分布是一种连续概率分布,由两个参数决定:均值(μ)和标准差(σ)。
请生成服从正态分布的模拟数据:
【代码 9-3】使用中文本地时间格式化输出MovieLens数据文件“u.data”中用户评分时间信息:
【代码 9-4】利用MovieLens用户评分数据文件“u.data”,按照星期几统计每周所有用户的评分次数与平均评分:
【代码 9-5】利用键盘控制绘图,如使用A向前绘制50像素,左箭头左转方向90度,并同时允许鼠标点击时直接绘制到点击位:
【代码 9-6】绘制指定两种颜色之间的渐变效果:
【代码 9-7】柱状图是一种常见的数据可视化方式,经常用于显示统计分组后的离散数据。请根据列表数据绘制柱状图:
【代码 9-8】统计《红楼梦》关键人物在同一段落中共现的次数:
【代码 9-9】显示《红楼梦》相关高频词语的词云:
【代码 9-10】利用DeepSeek实现单次大语言模型对话:
【代码 9-11】利用DeepSeek实现多轮大语言模型对话:
【代码 9-12】抽取网页中的所有汉字(https://www.njcie.com):
【代码 9-13】点击按钮可以输出内容的简单窗体:
【代码 9-14】累加两个数字之和的计算器:
【代码 9-15】最简单的静态Web网页:
【代码 9-16】将用户输入的内容再次显示出来的Web网页:
主代码文件Exec.py:模板网页文件index.html:
【代码 9-17】对名称为“ocr.jpg”的图片进行文字识别:
【代码 9-18】利用Flask构建在线语音合成界面:
第十章 NumPy数值处理(点击代码可复制)
【代码 10-1】生成由一千个随机浮点数组成的一维数组:
【代码 10-2】返回离数组平均值最近的数组元素值:
【代码 10-3】数据预处理是各类机器学习方法必须的前提工作。常见的数据问题有缺失值、异常值等问题。请利用NumPy实现使用列均值来填充二维数组的缺失值:
【代码 10-4】数值分析是各类机器学习方法常见的基础性工作,尤其是相关性分析,它可以帮助去除冗余特征,实现特征选择与优化,提高模型性能,而且通过相关性分析有助于理解特征关系和进行重要性评价,从而提高模型的可解释性。
现有“pricesFull.csv”文件,记录了部分商品的相关价格数据信息:
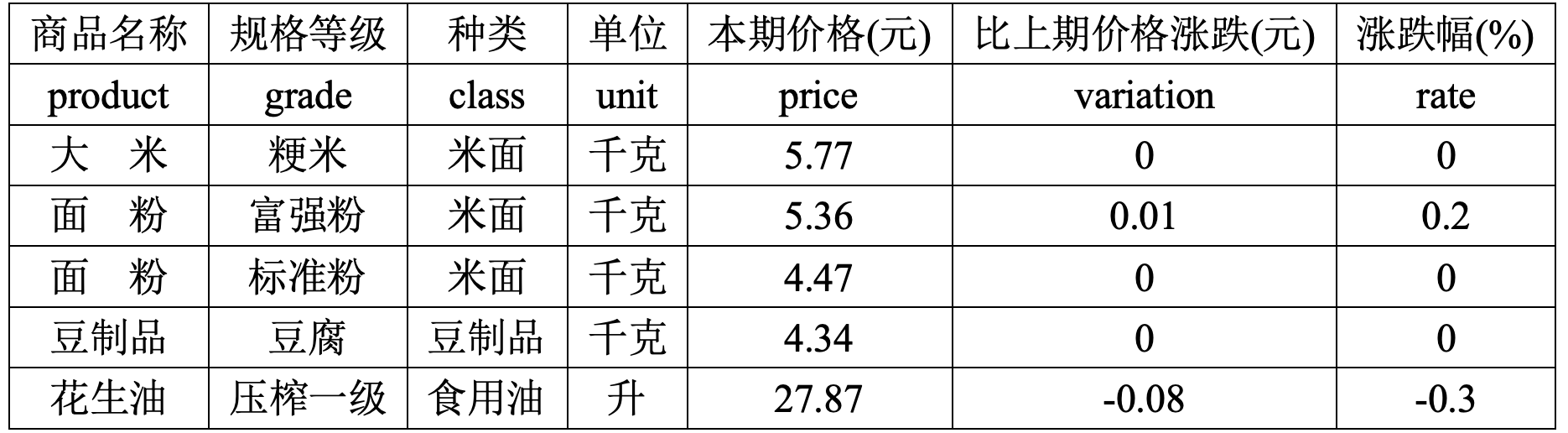 请计算“本期价格”与“涨跌幅”的数据相关性。
请计算“本期价格”与“涨跌幅”的数据相关性。
第十一章 Pandas数据查询(点击代码可复制)
【代码 11-1】查询每位读者借阅数量最多的年份及其借阅量:
【代码 11-2】k-means是一种常见的无监督机器学习聚类算法。其步骤主要为:
①初始化:随机选择K个初始簇心(centroids)。这些簇心可以是从数据集中随机抽取的数据点,或者使用其他方法如K-means++进行更智能的初始化,以提高收敛速度。
②分配数据点到簇:对每个数据点,计算其与K个簇心之间的距离(通常使用欧几里得距离)。将每个数据点分配给距离其最近的簇心,形成K个簇。
③更新簇心:重新计算每个簇的簇心,新的簇心是当前簇中所有数据点的均值(质心)。
④迭代:重复步骤2和步骤3,直到簇心不再发生显著变化(收敛),或者达到预设的最大迭代次数。
通过以上步骤,K-means算法能够找到K个簇,使得每个簇内的数据点尽可能相似,而不同簇之间的数据点尽可能不同。该算法的性能和结果受到初始簇心选择、K值的选择以及数据分布的影响。因此,在实际应用中,可能需要尝试不同的初始化方法、K值和数据预处理技术,以获得最佳的聚类效果。
现有十个二维坐标点:
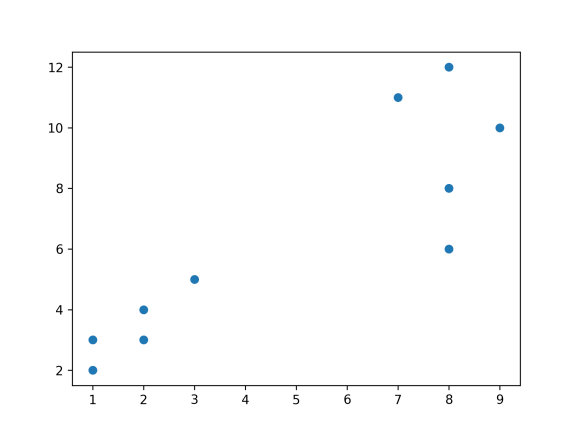 请使用k-means聚类算法聚为两类:
请使用k-means聚类算法聚为两类:
【代码 11-3】利用MovieLens提供的用户评分数据(“u.data”)、用户信息(“u.user”)和电影信息(“u.item”),统计男女不同观众对各个年代电影的观影次数,其中年代以20年为单位来计算:
第十二章 数据可视化(点击代码可复制)
【代码 12-1】在读者借阅数据中,每天的借阅量和每天最高的单人借阅量是两个不同的借阅情况评价指标。请使用散点图分析两种数据的关系:
【代码 12-2】代码 7-5使用类来封装各种时间数据单元,并使用继承方法得到时间预测类,根据最小二乘法实现了简单线性回归时序预测模型。在此基础上,绘制已有的原始点、预测点和拟合的线性回归线:
【代码 12-3】代码 11-2介绍了无监督机器学习聚类算法k-means的实现,对十个二维坐标点使用k-means聚类算法聚为两类。在此基础上,绘制已有的原始点和质心,并使用不同颜色区分两个类:
第十三章 机器学习(点击代码可复制)
【代码 13-1】查看二手车交易记录中缺失数据所在的行列位置:
【代码 13-2】在机器学习分类算法中,有两个常见指标,分别是精确率(Precision)和召回率(Recall)。所谓精确率,是指在分类模型预测为正例的所有样本中,实际为正例的样本所占的比例。而召回率是指在模型预测为正例的所有样本中,实际为正例的样本在全部正例样本的比例。精确率反映了模型对正例的识别能力,召回率可以测度全面捕获实际正例的能力。对于分类预测而言,虽然精确率和召回率这两个指标都是越高越好,但是在实际应用中,它们更容易产生此升彼降的“跷跷板”效应。虽然目前无法证明这种情况一定存在,但是在经验上却符合人们的认知。因为召回率会随着返回结果数量的增多而更有可能指标值上升,反之精确率却会因为返回结果数量增多后带来的更多错误判断而导致指标值下降。
请结合模拟数据,使用任一分类模型,绘制不同精确率下的召回率,形成所谓的PR(Precision-Recall)曲线:
【代码 13-3】结合每日需求预测订单数据集“Daily_Demand_Forecasting_Orders.csv”(网址为:https://archive.ics.uci.edu/dataset/409/daily+demand+forecasting+orders,也可以在教学资源中下载)。这些数据来自于一家巴西物流公司60天内的相关数据,有12个与订单相关的特征数据,最后一个“Target (Total orders)”列表示订单总量。可以通过前面12个特征来预测订单总量。请使用回归模型,完成该订单总量预测模型构建:
【代码 13-4】利用Sequential模型实现企业审计数据风险列的分类预测: