在如今的信息化时代,互联网中实体类别多样化,且粒度更细并具有层次,相对于类别有限的传统命名实体,人们开始将目光转向开放域实体,哈工大社会计算与信息检索研究中心推出的《大词林》是一个自动构建的大规模开放域中文实体知识库。
实体是文本中承载信息的重要语言单元。按照Automatic Content Extraction(ACE)评测计划的定义,实体在文本中的引用可以有三种形式:命名性指称、名词性指称和代词性指称,在自然语言处理领域,命名性的指称被称为“命名实体(Named Entity,简称NE)”。
MUC-6(1995)首次提出命名实体识别任务,旨在识别出实体概念的命名性指称,即命名实体,并标明其类别,实体的类别是实体概念上外延更广的主题词,也被称为实体上位词,和实体具有上下位关系。起初,识别的实体类别有人名、地名、机构名,但这些实体类别很局限,并不能满足实际的需求。在此基础上,又有诸多的实体类别定义,如:ACE-2007将实体分为7大类、45小类,Yosef(2013)将实体分为505类。
上述将命名实体的类别进行人为的定义,其优点在于可以将命名实体识别中标明实体类别的过程看作分类问题,然后应用传统的模式分类方法解决该问题。然而,预先对类别进行定义也有其不可避免的缺陷:人工定义的类别覆盖程度有限且不易更新,当涉及新的领域时,实体类别体系可能需要重新定义。
在如今的信息化时代,对于互联网中的海量实体很难由人工预先定义出一个完备的类别体系,这些实体被称为开放域实体,和传统命名实体相比,开放域实体有以下两个主要特点:
实体词的类别更多,且不限定。比如可能的类别包括药品、动物、植物、赛事、会议、菜肴等等,远远多于传统命名实体。而且随着社会的进步,一些新的类别可能出现,因此*人工难以确定一种固定的完备的类别体系。
实体词的类别粒度更细,且有层次。比如传统命名实体中的机构名可以进一步细分为:学校名、公司名、政府部门名、新闻机构名等;学校名则还可以继续细分为高校名、中学名、小学名等。这些类别通过上下位关系连接,构成一种偏序结构。
由此可见,对于开放域实体,已无法将其类别标定简单地看作分类问题。
近年来,一些学者或机构开始为开放域实体构建知识库,以更好地为信息抽取、信息检索、开放域问答等自然语言处理任务提供支持。其中包含实体类别的知识库有英文的WordNet、汉语的知网(HowNet)以及《同义词词林》等。哈工大社会计算与信息检索研究中心为了扩充《同义词词林》,利用已有的汉语词语相关资源并投入大量的人力和物力,完成了一部具有汉语大词表的《哈工大信息检索研究室同义词词林扩展版》(以下简称《同义词词林(扩展版)》),最终的词表包含 77,343 条词语。
但这些知识库需要领域专家的人工构建,使得构建的过程耗时费力从而无法大规模化,对互联网中海量开放域实体的覆盖程度极为有限。
2014年11月,哈工大社会计算与信息检索研究中心推出自动构建的大规模中文实体知识库――《大词林》,相比于上述提到的开放域实体知识库,《大词林》的构建不需要领域专家的参与,而是基于多信息源自动获取实体类别并对可能的多个类别进行层次化,从而达到知识库自动构建的效果。同时也正是由于《大词林》具有自动构建能力,其数据规模可以随着互联网中实体词的更新而扩大,很好地解决了以往的人工构建知识库对开放域实体的覆盖程度极为有限的问题。
另外,相比以往的类别体系知识库,《大词林》中类别体系的结构也更加灵活。如《同义词词林(扩展版)》中每个实体具有具备五层结构,其中第四层仅有代码表示,其余四层由代码和词语表示,而《大词林》中类别体系结构的层数不固定,依据实体词的不同而动态变化,如“哈工大”一词有7层之多,而“中国”一词有4层;另外,《大词林》中的每一层都是用类别词或实体词表示。

《大词林》中“哈工大”的类别体系
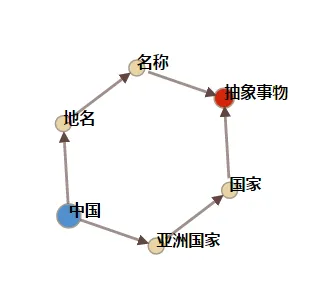
《大词林》中“中国”的类别体系
自2014年11月27日上线,《大词林》不断添加中文实体及其层次化类别信息,自动构建开放域实体知识库。目前,《大词林》中包括约250万实体、约15万个类别;平均每个命名实体有1.32个不同粒度的类别;上下位关系超过330万,其中实体与上位词之间的上下位关系与上位词之间的上下位关系准确率均达到90%以上。
《大词林》系统网站(http://www.bigcilin.com/,点击文末【阅读原文】即可访问)支持用户查询任意实体,并以有向图的形式展现实体的层次化类别,同时支持以目录方式供用户浏览部分公开的知识库。
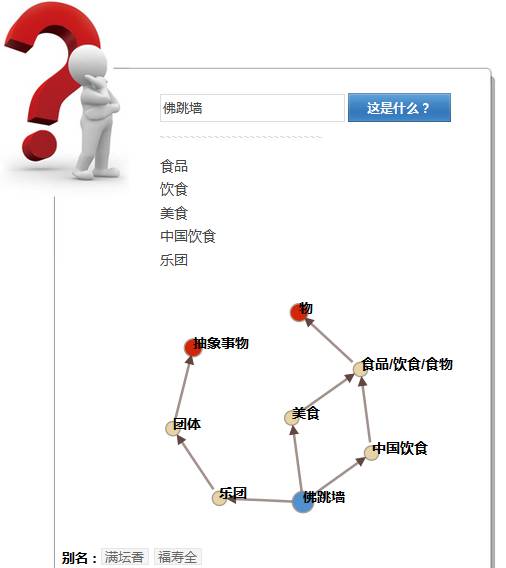
《大词林》以有向图的形式展现实体的层次化类别及关系
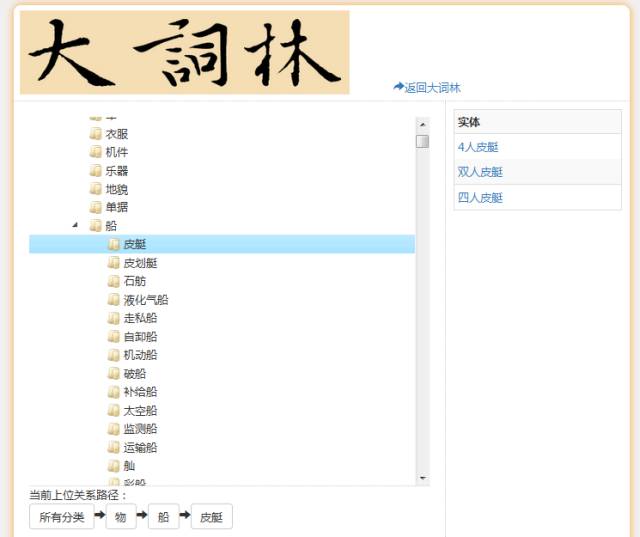
《大词林》支持以层次化结构展现部分知识库
人工智能中关键的一步是知识的获取与构建,《大词林》作为基于上下位关系的中文知识库,随着互联网中实体词的增加不断扩充其数据规模,并即将加入实体间关系、实体属性等网状关系结构,这对于基于知识库的智能系统无疑是一笔巨大的宝藏。目前《大词林》已被科大讯飞、腾讯、奇虎360等多所公司以及高校付费使用。
本文执笔:姜天文


 加好友
加好友  发短信
发短信
 管理员
管理员
 Post By:2016/5/9 18:44:22 [只看该作者]
Post By:2016/5/9 18:44:22 [只看该作者]






